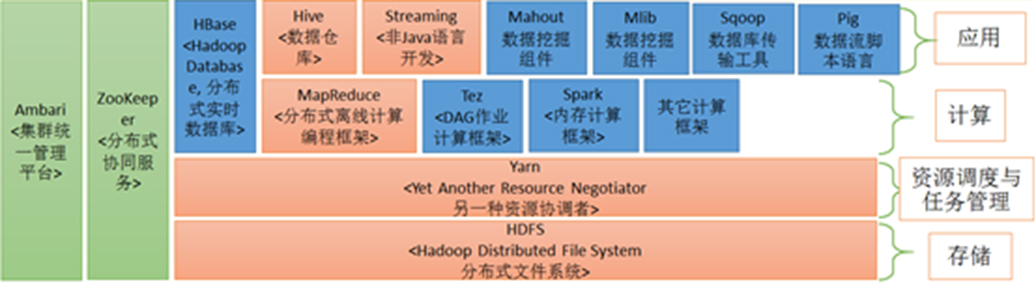
1.Hive在Hadoop生态圈地位
2.数据仓库和数据库的对比分析
同:
都是用来存储数据均为数据的存储载体
数据仓库也是数据库,是数据库的一种衍生,延深应用
数据仓库和数据库间存在数据交互,相辅相成各有千秋
异:
数据库面向事务设计,数据仓库面向主体设计的
数据库设计避免冗余,数据仓库刻意引入冗余
数据库一般存储在线交易数据,实时性强存储空间有限。数据仓库一般是历史数据,实时性弱但存储空间庞大
数据库是为捕获数据而设计,即实时性强吞吐量弱,数据仓库是为分析数据而设计,即吞吐量强实时性弱。
3.Hive操作
和数据库操作语言类似
4.Hive数据模型
5.数据类型
Varchar和char对比说明
同:
都是存储数据的类型
异:
varchar变长
节省数据空间,不利于计算
用时间换空间
char 定长
浪费了存储空间,节省了计算时间
用空间换时间
6.数据操作分类
DDL:对表的操作
DML:数据插入
DQL:数据查询
7.HiveSQL
元数据:描述数据的数据
表分类:内表和外表
概念说明:
hive表分为两类,即内外表。以元数据和实体数据的操作权限作为分类依据
特点特征:
内表:元数据和实体数据都归hive管理,一删全删。
外表:元数据归Hive管,实体数据归HDFS,删表只会删除Hive元数据,不会改变实体数据
应用场景:
数据表生成时,如果是hive内部自生成的表则统一设置内表,如果不是自生成的,而是外部导入的,则设置为外表。
代码实现:
Create [external] table ……
external内外表唯一区分关键字。
7.1 DDL建表模板
关键词解释
• external: 创建内部表还是外部表,此为内外表的唯一区分关键字。
• comment col_comment: 给字段添加注释
• comment table_comment: 给表本身添加注释
• partitioned by: 按哪些字段分区,可以是一个,也可以是多个
• clustered by col_name… into num_buckets BUCKETS:按哪几个字段做hash后分桶存储
• row format:用于设定行、列、集合的分隔符等设置
• stored as : 用于指定存储的文件类型,如text,rcfile等
• location : 设定该表存储的hdfs目录,如果不手动设定,则采用hive默认的存储路径
查看已存在表的详细信息:show create table/desc tablename
显示表:show tables;
更改表:alter table xxx rename xxx1;
增加字段:alter table xxx1 add columns(age int comment “新增加的列”)
视图(虚表)
本身不存储实际数据,只存储表关系,使用时再去通过关系查找数据。
7.2 DML数据加入
加载数据脚本:
新版已不支持本地数据文件加载到表中。
可以选择 1.rz -bye 2.hdfs dfs -put xxx.txt /tmp/…
加载HDFS数据文件的脚本
注:原始的hdfs文件数据将被move到目标表的数据目录中。
将查询结果插入到数据表中
多插入模式(一次查询多次插入)
表数据删除的三种方法
drop,delete,truncate
1.drop 是把数据和元数据全部干掉。
2.delete 按照条件删除数据。只会删掉实体数据, 其它数据包括元数据、状态数据均不会改变。
3.Truncate 截断数据,是指将全部数据删除掉。元数据不动,但状态数据会随之删掉。
将查询结果写入HDFS目录
外表删除
删除外部表后的数据变动情况(删除表后,hdfs文件依然存在)
join查询
• inner join:左表和右表满足联接条件的数据,全部查询出来
• left outer join:以左表为主,将左表数据全部保留,右表没有关联上数据字段置成NULL
• full outer join:没有关联数据全部置成NULL
union
• union all:将所有表数据,完全叠加在一起,不去重。
• union:将所有表数据,完全叠加在一起,总体去重。
函数
if( Test Condition, True Value, False Value )
coalesce( value1,value2,… )将参数列表中第1个不为null的值作为最后的值
case [ expression ] WHEN condition1 THEN result1
when condition2 THEN result2
else result
end
split 将字符串拆分成一个数组
explode:将一个集合元素,打散成一行一行的组成,即将一行改成多行,换句话说行转列
lateral view:与explode联用,形成一张新表
select id,name,score from user_score lateral view explode(split(score_list,’,’)) score_table as score;
来源:CSDN博主
原文链接:https://blog.csdn.net/m0_49142509/article/details/120957785
